
티스토리 뷰
출처 : https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/
3. Word Embeddings use case scenarios
Since word embeddings or word Vectors are numerical representations of contextual similarities between words, they can be manipulated and made to perform amazing tasks like-
- Finding the degree of similarity between two words.
model.similarity('woman','man')0.73723527 - Finding odd one out.
model.doesnt_match('breakfast cereal dinner lunch';.split())'cereal' - Amazing things like woman+king-man =queen
model.most_similar(positive=['woman','king'],negative=['man'],topn=1)queen: 0.508 - Probability of a text under the model
model.score(['The fox jumped over the lazy dog'.split()])0.21
Below is one interesting visualisation of word2vec.
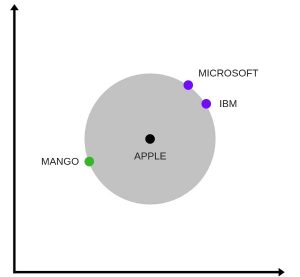
The above image is a t-SNE representation of word vectors in 2 dimension and you can see that two contexts of apple have been captured. One is a fruit and the other company.
'Study' 카테고리의 다른 글
| L1 Regularization, L2 Regularization (0) | 2019.09.27 |
|---|---|
| GCP 우분투에서 csh, tcsh 설치하기 (0) | 2019.04.11 |
| Word2Vec 트레이닝 방식 이해 (0) | 2017.09.05 |
| 공부하기 좋은 자료 #2 (0) | 2017.08.31 |
| 공부하기 좋은 사이트 #1 (0) | 2017.06.16 |